
Why Dashboards Are Wrong: The Real Reasons Teams Lose Trust
Jun 19, 2026 / 39 min read
June 19, 2026 / 46 min read / by Team VE
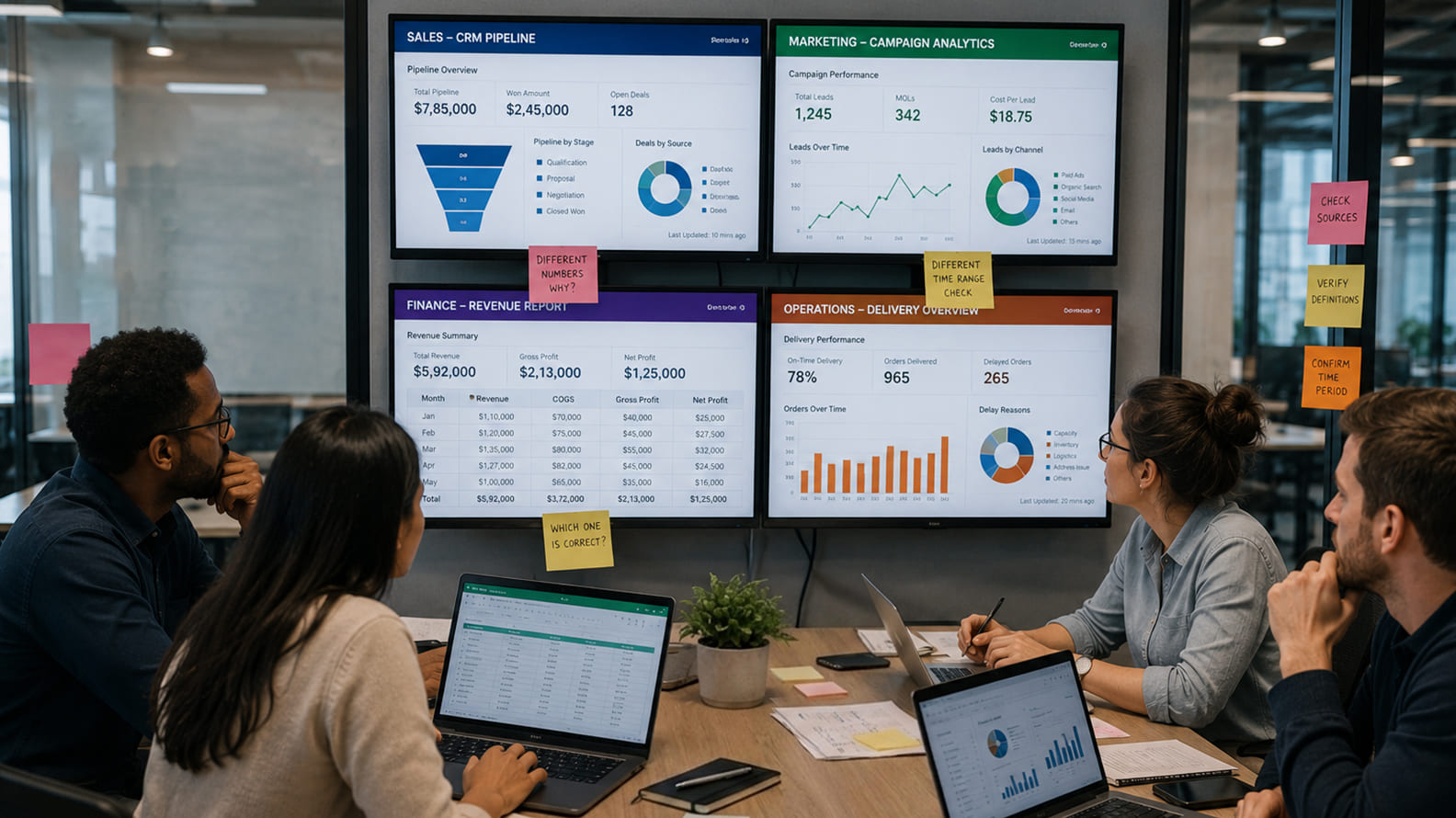
When marketing, sales, finance, and operations report different numbers for the same KPI, the dashboard is rarely the real villain. The mismatch usually begins deeper inside definitions, source systems, date logic, refresh windows, joins, exports, and ownership.
Dashboard mismatch is what happens when a company tries to make one business number serve too many meanings. Marketing may report leads from campaign conversions. Sales may report qualified CRM records. Finance may report invoiced or recognized revenue. Operations may report delivery-ready accounts. Every team may be working from a valid system, but the company still ends up arguing because the metric has never been governed properly.
A senior data analyst does not begin by redesigning the dashboard. The work starts by tracing the number back to the business event that created it. What counted as a lead? Which date grouped the record? Which system owned the source? When did the dashboard refresh? Did a join multiply the rows? Was an Excel export adjusted manually? Who owns the final definition? Until those questions are answered, a cleaner dashboard only makes the disagreement look more professional.
Dashboard mismatch, also called KPI mismatch, dashboard data inconsistency, or reporting discrepancy, happens when two or more dashboards show different numbers for what appears to be the same metric.
For example, the sales dashboard says revenue is $120,000, the finance dashboard says it is $108,000, and the leadership report shows another number altogether. At first, everyone thinks they are looking at the same KPI. In reality, each dashboard may be using a different definition, source system, date range, refresh schedule, filter, join logic, attribution rule, or manual adjustment.
That is why dashboard mismatch is rarely just a “dashboard problem.” The dashboard is only the final screen. The real issue usually sits deeper in the reporting chain: how the KPI is defined, where the data comes from, how it is cleaned, how often it refreshes, who owns the metric, and which version the business treats as the source of truth.
A useful way to understand dashboard mismatch is to look at what happens when data moves through too many systems without enough control. In 2020, England’s COVID-19 reporting process missed 15,841 positive cases after a technical issue in the automated transfer of test data, and later reporting explained that the problem was linked to the way Excel files were used in the process.
The UK Government dashboard note recorded that 15,841 additional cases had to be added later, while the BBC’s explanation of the Excel issue showed how a file and process limitation could turn into a major reporting failure.
That is not the same as a marketing or sales dashboard dispute, but it is a relevant reminder for business reporting: once data passes through tools, exports, system limits, transfers, and human assumptions, the final number can look official while still being incomplete.
Inside a company, the stakes are commercial rather than public health, but the pattern is familiar. Marketing says the business generated 4,200 leads. Sales says the CRM shows 2,850 usable leads. Finance says neither number can go into the board pack because only part of that activity has turned into invoiced or recognized revenue. Everyone opens a dashboard. Nobody agrees. The room starts asking which report is wrong, but the sharper question is why the business expected one number to describe three different stages of reality.
That is where good analytics work changes the conversation. The analyst does not begin with the chart. They begin with the path of the number. A lead may start as a campaign conversion, become a form submission, turn into a CRM record, get merged with an existing contact, get qualified by sales, and eventually become an opportunity.
Salesforce’s own lead-conversion model shows why this split happens: a qualified lead can become a contact, be connected to an account, and, when a deal is being worked, be linked to an opportunity. That means a marketing dashboard counting initial interest and a sales dashboard counting qualified pipeline are not necessarily contradicting each other. They may be counting different business moments inside the same funnel.
Revenue has the same problem. A sales dashboard may show a closed-won deal in April, billing may show an invoice in May, and finance may recognize revenue later depending on delivery or accounting rules. Under the ASC 606 revenue model, revenue recognition is tied to when control of promised goods or services transfers to the customer, which is why bookings, invoices, collections, and recognized revenue should not be collapsed into one dashboard label. A dashboard only shows the final expression of a business journey. If the journey is not governed, the number will not be trusted.
This is why dashboard mismatch is rarely just a dashboard problem. The screen is where the disagreement becomes visible, not where it begins. The real issue may be that teams are using different definitions, different source systems, different date fields, different refresh windows, different filters, or different manual corrections. In many companies, the argument is not actually about a chart. It is about the absence of one agreed business rule.
A strong dashboard should therefore do more than display a number. It should make the number understandable. It should tell users what the metric means, where it came from, when it refreshed, what it includes, what it excludes, which date logic it uses, and who owns the definition. Without that context, even a well-designed dashboard can become a source of confusion.
Most dashboard mismatch begins with business terms that look simple until teams start reporting on them. Lead. Customer. Revenue. Churn. Active account. Pipeline. Conversion. These words sound obvious in a meeting, so people assume everyone is using them the same way. Inside systems, each word becomes a rule, and that is where the numbers start to split.
Take “lead” as an example. Marketing may count anyone who fills a form, registers for a webinar, downloads a guide, clicks a campaign CTA, or starts a chatbot conversation. Sales may count only CRM records that have a valid company name, work email, geography, budget range, and buying intent.
A sales manager may go one step further and report only accepted leads that the team has agreed to pursue. A leadership dashboard may care only about leads that become qualified opportunities. Each number can be useful, but only when the stage is clear.
This is also why CRM dashboards often differ from campaign dashboards. A campaign tool may record the first conversion. A CRM may merge that person with an existing contact, reject a duplicate, assign the record to an owner, or move the person into an account and opportunity workflow.
Salesforce’s own lead-management guidance explains how leads can move into account, contact, and opportunity structures as they progress through the sales process. Once that happens, the original marketing count and the sales pipeline count are no longer measuring the same business moment.
Revenue creates the same confusion. Sales may use revenue to mean closed-won bookings. Billing may use it to mean invoices raised. Finance may use it to mean recognized revenue. Cash reporting may use it to mean money collected. A delivery team may look at revenue through the lens of work that has started or accounts that are ready to serve. If all of these dashboards use the label “revenue,” the disagreement is built into the reporting before anyone opens the chart.
The fix starts with sharper definitions. A useful metric definition should explain:
A weak definition says, “A lead is a potential customer.” A useful definition says, “A qualified lead is a deduplicated CRM record created from an approved acquisition source, with valid contact details, inside the target geography, accepted by sales, and grouped by sales-accepted date.” That level of clarity may feel detailed, but it is what allows different teams to stop rebuilding the same metric in their own way.
Lead dashboards create conflict because the word “lead” is often used before the business has decided which stage it is talking about. A paid-search conversion, a webinar registration, a demo form, a newsletter signup, a chatbot inquiry, a content download, and a referral form can all create a lead-like signal. Some of those people are serious buyers. Some are early researchers. Some are students, vendors, competitors, job seekers, existing customers, or duplicate records created by the same person using a different email.
This is why marketing and sales often look at the same funnel and report very different numbers. In Google Ads, a conversion action can track actions such as purchases, sign-ups, form submissions, phone calls, or other valuable website events through Google Ads conversion tracking.
That is useful for campaign optimization because marketing needs to know which channel is creating responses. But a campaign conversion is not automatically a sales-ready lead. It is a signal that someone completed an action the business decided was worth tracking.
Once that person enters the CRM, the number starts changing. A CRM may reject the record because the email is invalid, merge it with an existing contact, attach it to an account, assign it to an owner, or move it through qualification.
Salesforce’s own guidance on converting qualified leads shows how a lead can become a contact, be linked to an account, and, when there is a potential deal, be connected to an opportunity. At that point, the marketing count and the sales count are no longer meant to match exactly. Marketing is often counting demand signals. Sales is counting records worth working.
HubSpot’s lifecycle stage model shows the same reality in a different language. A contact can move through stages such as subscriber, lead, marketing qualified lead, sales qualified lead, opportunity, customer, evangelist, or other custom stages depending on the business setup. Those labels exist because the funnel is not one event. It is a sequence. When a dashboard collapses that sequence into one “leads” number, it removes the context teams need to understand quality.
A simple B2B example makes the mismatch clear. A campaign generates 1,000 form fills in a month. After removing duplicates, personal emails, students, vendors, unsupported geographies, and existing customers, marketing may have 620 valid inquiries.
Sales may accept 310 after checking company fit, budget, role, and intent. Out of those, 90 may become sales-qualified opportunities, and 18 may close over the next quarter. Those are not four versions of the same number. They are four stages of the same commercial journey.
The reporting problem begins when leadership asks, “How many leads did we get?” without specifying which stage matters for the decision. If the discussion is about ad efficiency, form fills and valid inquiries matter. If the discussion is about sales workload, accepted leads matter. If the discussion is about forecasts, opportunities matter. If the discussion is about revenue quality, closed-won customers matter.
A stronger dashboard shows the funnel in stages so the business can see where the number changes. If campaign conversions are high but accepted leads are low, the issue may be targeting, form quality, bot traffic, geography, job-title mismatch, or weak qualification rules.
If accepted leads are strong but opportunities are low, the issue may be sales follow-up, offer fit, pricing, timing, or discovery quality. If opportunities are strong but closed-won revenue is weak, the problem has moved further down the commercial chain.
A lead number without lifecycle stage, source, deduplication rule, qualification rule, and date logic is too loose to guide decisions. Once those rules are visible, the argument becomes more useful because teams can see where the funnel is changing shape instead of defending one flat number.
Two dashboards can use the same customer record and still place it in different months. This happens because every team uses the date that fits its work. Marketing may group a lead by the day the form was submitted. Sales may group the same account by the day an opportunity was created. Finance may use invoice date, payment date, or revenue-recognition period. Customer success may use activation date, renewal date, cancellation date, or service-start date.
A simple deal can move through all of these dates. A prospect fills a form on March 28. Sales creates the opportunity on April 3. The deal closes on April 29. The invoice goes out on May 2. Payment arrives on May 18. Delivery starts in June.
If the leadership team asks for “April performance,” marketing may not include the lead because the inquiry came in March. Sales may include it because the opportunity was created and closed in April. Finance may leave it out because invoicing happened in May or revenue begins later.
This is one of the cleanest reasons dashboards disagree. Nobody has changed the record. The business is simply using different moments in the same journey. The confusion becomes sharper in tools where date fields carry specific meanings.
In a CRM, an opportunity may have a created date, stage-change dates, close date, owner-change dates, and last-activity dates. Salesforce, for example, treats opportunity fields as part of how teams track deal timing, value, stages, and close expectations. A sales dashboard built on opportunity-created date will not match a dashboard built on close date, even when both are pulling from Salesforce.
Marketing tools have their own timing logic. Google Analytics 4 explains that data processing and attribution can take time, so recent campaign numbers may change after the first view. That means a same-day or next-day marketing dashboard may show a useful early signal, while a later report may show the more settled version. If sales is already looking at CRM records and marketing is still dealing with attribution updates, the two dashboards can look inconsistent even when both are behaving normally.
Finance adds another layer because revenue timing is rarely the same as sales timing. A sales team may celebrate a closed-won deal in April, but accounting may recognize revenue only when the promised goods or services are delivered.
Deloitte’s explanation of ASC 606 revenue recognition centers on recognizing revenue when control transfers to the customer, which is why bookings, invoices, collections, and recognized revenue often belong in separate reporting views.
This is why a dashboard should make its date logic visible. A report titled “April revenue” is too vague if one team reads it as bookings, another reads it as invoices, and finance reads it as recognized revenue. The title, filter, tooltip, or metric note should say which date is being used.
Good date labels make dashboards much easier to trust:
Dashboard mismatch often appears when teams compare numbers at different stages of processing. A sales dashboard may update from the CRM every hour while a marketing dashboard may still be processing campaign events. Similarly, a warehouse model may refresh overnight but a finance report may wait for month-end close. Each report may be doing its job, but the numbers will not always line up at the same moment.
This happens most often when people treat every dashboard as if it is live and final. In reality, many dashboards are snapshots. Some show early movement. Some show cleaned data. Some show final numbers after corrections, merges, adjustments, or accounting review.
Marketing data is a common example. Google Analytics 4 explains that data processing can take 24 to 48 hours, and attribution can keep changing for a period after the event. So a campaign report checked this morning may show one version of yesterday’s performance, while a report opened later may show a more settled number.
If the CRM has already created leads from form submissions and the analytics tool is still processing attribution, the two dashboards may appear to disagree even though both are working within their own timing rules.
The same pattern shows up in revenue reporting. Sales may close a deal today and see the opportunity reflected immediately in the CRM. Billing may not show anything until the invoice is raised. Collections will update only when payment comes in.
Finance may finalize the number after adjustments, credits, taxes, recognition rules, or month-end review. A leader comparing those reports on the same afternoon may see four different numbers because the business event has not reached every system in the same form yet.
Data pipelines add another timing layer. Tools such as Fivetran explain that sync frequency controls how often data moves from source to destination, and the interval can vary depending on setup. That means a CRM record may exist in the source system before it appears in the warehouse, BI model, or downstream dashboard. If a sales manager checks the CRM at 11 a.m. and an analyst checks the BI dashboard before the next sync, both are looking at valid systems at different moments.
This is why fresh information should be visible in the report itself. A dashboard should show when it last refreshed, how often it refreshes, whether the current period is still open, and whether late-arriving data can change the number. That small context prevents a lot of unnecessary arguments.
Useful dashboard labels include:
Revenue dashboards create tension because one commercial relationship can pass through several reporting stages before it becomes a number finance is comfortable closing. Sales sees the customer agreement first. Billing sees the invoice. Collections sees the payment. Finance sees the accounting period. Delivery sees the work that must now be staffed, fulfilled, and measured for margin.
Take a software implementation company. A client signs a $72,000 contract in late April, with onboarding in May, monthly billing from June, and support running for the rest of the year. The sales dashboard may show the full contract value in April because the deal was won.
Billing may show nothing until the first invoice is raised. Collections may show revenue only after payment lands. Finance may spread recognition across the service period because revenue-recognition standards such as IFRS 15 are built around the transfer of promised goods or services to the customer.
A mismatch appears when every dashboard calls its number “revenue” without saying which stage it is measuring. One team is looking at commercial momentum. Another is looking at invoices. Another is looking at cash. Another is looking at recognized revenue. The numbers differ because the business event has moved from sales commitment to billing action to payment collection to accounting recognition.
This matters even more in SaaS, outsourcing, retainers, managed services, and implementation-heavy contracts because value is rarely created in one clean step. A customer may sign now, start later, get billed in phases, receive credits, expand mid-contract, pause delivery, or churn before the full value is realized. If the dashboard hides these stages, leadership can easily overread a strong bookings month or underread a month where finance is still waiting for revenue to become recognizable.
A useful revenue view separates the stages clearly:
Once these stages are visible, the conversation becomes sharper. Strong bookings with weak invoicing may point to contract setup, onboarding delays, or billing triggers. High invoices with weak collections may point to payment terms, disputes, follow-up, or client cash issues.
Healthy recognized revenue with weak margin may point to delivery cost, staffing mix, scope creep, or poor utilization. The dashboard is no longer asking one “revenue” number to explain every part of the commercial chain.
The label matters. “April closed-won bookings” tells users something different from “June cash collected” or “Q2 recognized revenue.” When the dashboard names the business event clearly, sales, finance, billing, and operations can use their own numbers without turning every review into a fight over which revenue figure is real.
Dashboard mismatch also appears because every system stores the customer according to the job it was built to do. A CRM is designed around accounts, contacts, owners, stages, activities, and opportunities. A billing tool is built around subscriptions, invoices, credits, refunds, payment status, and tax treatment.
A support desk is built around tickets, requesters, priorities, SLAs, agents, and resolution status. A product analytics tool is built around users, events, sessions, cohorts, and behavior.
One customer can therefore exist as several different objects across the business. In the CRM, the customer may be an account with three contacts and one open renewal opportunity. In billing, the same customer may be a subscription with two invoices, one credit note, and a failed payment.
In support, the same customer may appear through five tickets raised by different users. In product analytics, the customer may appear as thirty active users generating thousands of events.
This is why system-level dashboards often disagree even when every system is behaving correctly. A support dashboard may show the customer as highly active because ticket volume is high. A product dashboard may show low usage because only two users are logging in.
Billing may show the account as at risk because payment failed. Sales may show the renewal as healthy because the champion is still engaged. These are not duplicate truths. They are different operational views of the same relationship.
The mismatch becomes sharper when the business tries to combine these systems without deciding which system owns which fact. Stripe’s documentation around invoices and subscription billing is built around billing events such as invoices, payment status, credits, and collection workflows.
Zendesk’s support model centers on tickets and customer requests, where the key unit is a service interaction. Product analytics platforms such as Mixpanel organize reporting around events and user behavior, which is a very different grain from a CRM account or finance invoice.
A simple SaaS example shows how this plays out. Sales says the customer is active because the renewal opportunity is open and the account owner has a positive next step. Billing says the account is not healthy because the latest invoice is overdue. Support says the customer is unhappy because there are seven unresolved tickets.
Product says the account is barely using the platform because only one admin has logged in this month. Leadership asks for “customer health,” and every dashboard gives a different answer because each system is measuring a different part of health.
This is where ownership matters. The CRM can own pipeline and relationship status. Billing can own invoices, payments, refunds, and subscription status. Product analytics can own usage. Support can own ticket behavior and resolution. Finance can own recognized revenue and margin. A dashboard that combines these views needs to preserve those roles instead of flattening them into one vague customer score.
The analyst’s work is to connect the systems carefully. That means mapping account IDs, customer IDs, subscription IDs, user IDs, ticket requesters, and finance records without multiplying rows or mixing grains. It also means deciding which source wins when two systems disagree.
If billing says the invoice is unpaid, the CRM should not override that because the account owner feels confident. If product usage is low, the sales forecast should not hide it. If support tickets are rising, the customer-health view should show that pressure clearly.
These mismatches are often useful because they show the customer from different angles. A single system rarely carries the whole truth. The problem begins when the dashboard presents one combined number without showing the ingredients behind it.
A reliable cross-functional dashboard should make the source of each signal visible, so teams know whether they are looking at sales momentum, billing status, product adoption, support pressure, or finance outcome.
Some dashboard mismatches are easy to spot because the numbers obviously do not line up. Others are more dangerous because the chart looks clean, the filters work, the labels look professional, and the total is still wrong. This often happens when datasets are joined at the wrong grain.
Grain simply means what one row represents. One table may have one row per order. Another may have one row per order line. A customer table may have one row per customer. A campaign-touch table may have several rows per lead. A product-events table may have thousands of rows per user. The dashboard can go wrong when those tables are joined without protecting the original level of detail.
Take an ecommerce example. The orders table has one row for an order worth $1,000. The order-lines table has four rows because the order contained four products. If the analyst joins order revenue to the line-item table and then sums revenue after the join, the dashboard may show $4,000 instead of $1,000. Nothing on the chart may look broken. The error sits below the visual layer, inside the join.
This is why BI tools and semantic layers spend so much effort on modeling relationships properly. Looker’s documentation on symmetric aggregates explains the same problem through fanouts, where joins can duplicate rows and inflate measures if the model is not built carefully.
The issue is not limited to revenue. It can affect customer counts, conversion rates, average order value, churn, utilization, support volume, product usage, and almost any KPI built from multiple tables.
Marketing attribution is a common place where this happens. One opportunity may have five campaign touches. If the opportunity value is joined to every touch and summed without attribution logic, the dashboard may give each campaign the full deal value. Suddenly one $50,000 opportunity looks like $250,000 of influenced pipeline. The chart may look impressive, but the math has counted the same value several times.
Customer reporting has the same risk. One account may have thirty users. If account-level revenue is joined to user-level product events, the dashboard may repeat the same revenue across every active user. A product team may then think power users are producing more revenue than they really are. A customer-success team may overstate account activity. A finance dashboard may show inflated revenue after a join that looked harmless during report building.
Analysts usually catch this by checking totals before and after the join. If revenue is $1 million before a join and $1.6 million after, the join has changed the measure. If customer count rises after joining product events, the dashboard may be counting users or events instead of customers. If opportunity value grows after joining to campaign touches, attribution logic is probably missing.
A practical join review asks a few simple questions:
This is also where a governed metric layer helps. If revenue, pipeline, customer count, active users, and churn are calculated centrally, every dashboard builder does not have to recreate the same logic from scratch. The dbt Semantic Layer is one example of this approach, where teams define metrics centrally so downstream reports can reuse approved business logic instead of rebuilding calculations in separate dashboards.
When teams stop trusting dashboards, they usually return to spreadsheets. That happens quietly. A sales operations manager exports CRM data before the weekly review, removes duplicates, fixes owner names, excludes test records, and sends a cleaner number to leadership.
A finance manager downloads billing data, adjusts credits, removes cancelled invoices, and builds the month-end view in a workbook. A marketing analyst exports campaign data, manually remaps messy UTM names, and shares the “real” channel report in a spreadsheet.
This is understandable because spreadsheets are flexible. Excel is often the fastest place to investigate a mismatch, test a correction, group messy records, or explain what the dashboard missed. The problem begins when the same spreadsheet correction becomes part of the monthly reporting ritual. At that point, the official dashboard is no longer the real source of truth. The workbook is.
A simple sales example shows how this happens. The CRM dashboard says there were 1,240 leads in May. Sales ops says the usable number is 860 because 180 were duplicates, 90 were existing customers, 60 were outside the target market, and 50 had invalid contact details.
That cleaned number may be more useful for the meeting, but if the cleanup rules remain inside one person’s spreadsheet, the dashboard will keep showing 1,240 every month and the business will keep repeating the same argument.
The same pattern appears in finance reporting. A billing dashboard may show all invoices raised, while finance removes credits, cancelled invoices, intercompany entries, taxes, or items outside the reporting period before presenting the final number.
Those adjustments may be correct, but they need to move into governed reporting logic if they happen every close cycle. Otherwise, the finance workbook becomes the real revenue report, and the dashboard becomes only a starting export.
Spreadsheets also carry practical limits and control risks when they become infrastructure. Microsoft’s own Excel specifications and limits show that a worksheet has defined row, column, formula, and workbook limits, which is fine for analysis but risky for recurring operational reporting that keeps growing.
The bigger risk is not only size. It is that logic can sit in hidden columns, manual filters, copied formulas, local files, renamed tabs, or personal versions that others cannot easily audit.
A useful way to handle recurring spreadsheet fixes is to treat them as clues. If sales ops removes the same duplicate lead pattern every week, the deduplication rule belongs in the CRM, warehouse, or metric layer. If marketing repeatedly fixes campaign names, the business needs a governed naming convention and channel mapping.
If finance makes the same revenue adjustment every month, that rule should be documented and built into the reconciliation layer. If operations exclude the same inactive accounts before every utilization review, the definition of active account needs to be tightened.
Excel is still valuable for investigation, audit, ad hoc analysis, and explaining a mismatch quickly. It becomes dangerous when it quietly carries the rules that should live in the reporting system. A healthy analytics setup learns from those spreadsheets, moves repeated corrections upstream, and leaves the workbook for exploration rather than recurring truth-making.
Dashboards lose trust slowly. A report goes live, everyone uses it for a few months, and then the business changes around it. Sales renames stages. Marketing changes campaign naming. Finance adds a new revenue category.
Operations introduces a new service line. A CRM admin retires an old field. Someone adds a filter for internal records. Someone else creates a copy of the dashboard for a leadership meeting. The chart still loads, so people assume it still means what it meant earlier.
This is how ownership gaps turn into reporting gaps. If nobody owns the metric, nobody has the authority to settle what it means. If nobody owns the source data, field changes can break the report without warning. If nobody owns the dashboard, stale reports remain in circulation long after the business has moved on.
A practical example is “active customer.” Sales may call an account active if there is an open renewal or relationship activity. Finance may call it active if invoices are still being raised. Product may call it active if users logged in during the last 30 days. Customer success may call it active if the account is live and serviceable. If no one owns the definition, every dashboard can keep showing its own version and each team can defend its number honestly.
This is why data governance has to become operational, not ceremonial. IBM describes data stewardship as the work of managing data quality, usability, and governance across its lifecycle. In dashboard terms, that means someone has to care whether the metric is still defined correctly, whether the source field still works, whether the approved report is still the right one, and whether users know how to interpret the number.
Ownership usually needs three roles, even if the same person plays more than one in a smaller company:
Microsoft Power BI’s guidance on endorsing content through promotion and certification shows why this matters in large reporting environments. When datasets, reports, or semantic models are promoted or certified, users get a clearer signal about which assets are trusted for decision-making. That kind of endorsement does not solve definition problems by itself, but it helps stop teams from using random report copies as if they were official numbers.
The same principle applies outside Power BI. A leadership KPI needs a clear definition, a known owner, an approved source, and a certified reporting path. If the sales team has three pipeline dashboards, the business should know which one is used for forecasting.
If finance has a revenue model used for board reporting, the dashboard should say whether it shows bookings, invoiced revenue, collected cash, or recognized revenue. If marketing has several campaign reports, the approved one should state how channels, duplicates, test leads, and attribution windows are handled.
Without that ownership, dashboard mismatch keeps returning after every cleanup. An analyst may fix the report this month, but the next stage rename, campaign change, billing adjustment, or copied dashboard can reopen the same trust problem. Ownership is what keeps the number from drifting after the first fix.
Dashboard mismatch becomes easier to fix when the business stops treating it as one vague reporting problem. The number may be different on the screen, but the cause usually sits in one of a few places: the metric definition, the source system, the date field, the refresh window, the filters, the join logic, the spreadsheet adjustment, or the owner who approves the final rule.
A marketing and sales lead report is a good example. Marketing may count every form submission from the website. Sales may count only deduplicated CRM records that passed qualification. A dashboard may then show one team with 4,000 leads and another with 2,700.
The gap is not random. It may come from duplicates, invalid emails, existing customers, geography filters, sales-accepted status, or lifecycle-stage rules. If the report does not show those rules, the business is left arguing over the final number.
The same pattern appears in revenue, customer health, utilization, churn, and product activity. A SaaS company may call a customer active because the subscription is paid, while product analytics may call the same customer inactive because no user has logged in for 30 days.
A staffing company may report utilization by billed hours, while operations may report it by available capacity. A finance team may report revenue after adjustments, while sales reports closed-won value. The label stays the same. The rule changes underneath.
| Cause | What it looks like | What usually fixes it |
| Different definitions | Marketing counts all form fills as leads, while sales counts only qualified CRM records. | Create a metric dictionary that defines stage, inclusion rules, exclusions, owner, and approved source. |
| Different date logic | Marketing uses form-submit date, sales uses opportunity-created date, and finance uses invoice or recognition period. | Name the date logic inside the dashboard title, filter, tooltip, or metric note. |
| Source-system mismatch | CRM shows closed-won value, billing shows invoices, and finance shows recognized revenue. | Build a reconciliation bridge across CRM, billing, collections, recognition, and margin. |
| Refresh timing | CRM updates immediately, while the warehouse model refreshes later and finance waits for close. | Show last refresh time, expected latency, and whether the period is still open. |
| Manual exports | A manager cleans a CRM export in Excel before every review. | Move repeated spreadsheet corrections into governed transformations or documented adjustment rules. |
| Join problems | Order revenue is joined to line-item records and gets counted multiple times. | Check the grain before and after the join, then centralize approved measures. |
| Filter differences | One dashboard excludes test records, internal users, and existing customers, while another includes them. | Standardize global filters and label any dashboard-specific exclusions clearly. |
| Ownership gap | Nobody knows who approves the definition of active customer, churn, pipeline, or revenue. | Assign a metric owner, source owner, and dashboard steward for leadership KPIs. |
The practical work is to trace the mismatch from the dashboard back through the reporting chain. Power BI’s lineage view is useful because it shows how data moves from sources to semantic models, reports, and dashboards. That kind of lineage helps analysts see whether the same KPI is coming from the same model or whether teams are pulling from different datasets that only look similar on the surface.
For join and grain issues, the check has to go deeper than the dashboard visual. Tableau’s documentation on relationships and joins shows why tables need to be related carefully based on the level of detail in each source. If an order-level table is joined to a line-item table without protecting the measure, the dashboard may multiply revenue even though the chart itself looks perfectly clean.
Metric ownership also has to move from informal agreement to a reusable reporting layer. The dbt Semantic Layer is one example of defining metrics centrally so different tools can reuse approved business logic instead of rebuilding the same KPI separately in every dashboard, spreadsheet, and SQL query. The tool is not the main point. The discipline is. A metric should have one approved definition, even if different dashboards use it for different decisions.
Once the cause is named, the fix becomes much smaller. A lead mismatch may need lifecycle-stage rules. A revenue mismatch may need a bookings-to-recognition bridge. A churn mismatch may need an agreed cancellation date. A utilization mismatch may need a standard capacity denominator. The dashboard becomes easier to repair when the business knows exactly which rule broke trust.
A company usually asks for a new dashboard when the old one has lost trust. That can improve the design, but the mismatch returns if every team continues rebuilding the same KPI in its own tool. One analyst writes a SQL query for revenue, another creates a Power BI measure, a sales manager exports CRM data, finance adjusts the number in Excel, and marketing builds a campaign version in Looker Studio. The charts may look different, but the deeper problem is that the business logic is scattered.
This is why the metrics that create the most arguments should be defined in one governed place before they spread into dashboards. Leads, MQLs, SQLs, opportunities, bookings, revenue, churn, active customers, utilization, gross margin, and conversion rate should not be recreated from memory every time someone builds a report.
The definition should say what the metric counts, which source owns it, which date field it uses, which records are excluded, how duplicates are handled, and who can approve a change.
Tools can support this when the business has already agreed on the logic. Looker’s modeling layer, for example, lets teams define reusable business logic through LookML models, views, dimensions, and measures, so report builders are not recreating the same calculation differently in every dashboard.
In Microsoft environments, Power BI semantic models serve a similar purpose by giving reports a shared model for measures, relationships, and fields. The tool choice matters less than the discipline: the metric should be defined once and reused consistently.
A practical example is “sales-qualified lead.” If one dashboard counts every CRM lead marked SQL at any point in time, another counts only SQLs created this month, and a third excludes existing customers, the numbers will not match.
The fix is to define the metric clearly: a deduplicated CRM record, accepted by sales, inside the target market, excluding existing customers and test records, grouped by sales-accepted date. Once that definition is approved, every dashboard can reuse it instead of rebuilding the logic from scratch.
The same applies to revenue. Sales can still see bookings, finance can still see recognized revenue, billing can still see invoices, and collections can still see cash received. Those should be separate metrics with separate names, not four dashboards using one loose “revenue” label. Once the definitions are governed, the business can compare them as stages of the same commercial journey instead of treating them as conflicting answers.
A strong metric layer usually includes:
This does not have to begin as a huge data transformation project. Most companies can start with the handful of numbers leadership argues about most. If leads, revenue, churn, utilization, or pipeline keep changing across meetings, define those first. Once the business has one approved version of the metric, the dashboard becomes much easier to trust because the number is no longer being rebuilt differently in every corner of the company.
When dashboards disagree, the quickest mistake is to start fixing the visual layer first. Teams change charts, rename tabs, rebuild filters, adjust colors, and create a cleaner version of the same report. The dashboard may look better after that, but the mismatch remains if nobody has traced how the number was created.
A useful investigation starts with the number’s journey. Suppose marketing says April produced 4,200 leads, while sales says only 2,850 leads entered the CRM. The analyst should follow the count from the first event onward. Did the 4,200 include every form fill, including duplicates and existing customers?
Did bot submissions get removed? Did the CRM reject invalid emails? Were records merged into existing contacts? Did sales count only leads accepted by an owner? Did both dashboards use the same date field? Did one refresh before the other?
This kind of tracing is easier when the reporting environment shows lineage. Microsoft’s Power BI lineage view is built for exactly this kind of visibility because it helps teams see how data moves from sources to semantic models, reports, and dashboards.
In a larger data stack, lineage tools such as OpenLineage help document how datasets are created, transformed, and used across pipelines. The point is not the tool itself. The useful habit is to stop treating the dashboard as the starting point and follow the metric back through the chain that produced it.
A good reconciliation note should be simple enough for leadership to understand. For example:
“Marketing’s April lead number includes all campaign form submissions by form-submit date. Sales’ April number includes deduplicated CRM records accepted by sales by sales-accepted date. The difference comes from duplicates, invalid contact details, existing customers, unsupported geographies, and lifecycle-stage filtering. Going forward, acquisition reviews will use raw inquiries and valid inquiries, while sales-capacity reviews will use sales-accepted leads.”
That kind of note does more than settle one meeting. It gives each number a role. Marketing can still use raw conversion volume to judge campaign reach. Sales can use accepted leads to plan follow-up. Leadership can see where volume becomes quality. The dashboards no longer have to pretend they are measuring the same thing.
The same approach works for revenue. A reconciliation note might say that the CRM number shows closed-won bookings, the billing number shows invoices raised, the collections report shows cash received, and the finance dashboard shows recognized revenue for the accounting period.
Once that bridge is written, the mismatch becomes explainable. A strong sales month may not become recognized revenue immediately. A high invoice month may still have weak collections. A healthy bookings number may still create margin pressure if delivery costs are high.
The analyst should also check whether the mismatch comes from technical logic rather than business definition. A join may be multiplying rows. A filter may exclude internal users in one report but include them in another. A warehouse model may refresh overnight while the CRM updates hourly.
A manual Excel adjustment may be applied in finance but not in the BI dashboard. Each difference should be written down in plain language, because the business cannot trust a number it cannot explain.
A practical reconciliation usually covers:
Once the path is clear, the dashboard fix becomes much smaller. The team may need a renamed metric, a clearer tooltip, a certified source, a better join, a revised filter, or a bridge table between systems. Redesign comes after reconciliation because the visual should express the agreed logic, not hide unresolved disagreement under a cleaner chart.
Dashboard mismatch becomes expensive when it starts changing how people behave in meetings. Marketing arrives with one number, sales brings another, finance has a third while operations have already adjusted the export because the dashboard did not match delivery reality. The first twenty minutes go into defending sources, explaining filters, checking screenshots, and asking someone from analytics to confirm which number can be trusted.
That delay is the real cost. A company may have dashboards everywhere and still lack confidence in the decision in front of it. A hiring call gets postponed because utilization reports do not match. A campaign budget is paused because lead quality numbers differ across marketing and CRM reports.
A sales forecast is questioned because bookings, invoices, and recognized revenue have been mixed under one label. A delivery team is asked to ramp up based on a pipeline that finance does not yet recognize as real revenue.
This is why data quality cannot be treated as a technical hygiene issue. Gartner has often been cited for estimating that poor data quality costs organizations millions every year, and a recent ITPro discussion on BI and AI repeated the same larger point: BI, analytics, and AI all depend on trusted, connected, well-governed data.
The impact shows up as slower decisions, duplicated analysis, repeated reconciliations, weaker forecasting, and leaders who start relying on the person they trust rather than the dashboard the company built.
A familiar example is the monthly business review. The CEO asks why revenue is lower than expected. Sales says closed-won bookings are strong. Billing says several accounts have not yet been invoiced. Finance says recognized revenue will show later because delivery has not started.
Operations says staffing cannot be planned from bookings alone because some projects are still waiting for kickoff. The problem is not that any one team is being careless. The company is trying to make one “revenue” chart answer sales momentum, billing readiness, cash movement, accounting treatment, and delivery planning at the same time.
The same thing happens with lead reporting. Marketing may defend campaign performance because form fills are up. Sales may push back because accepted leads are flat. Leadership may ask whether the agency should be given more budget, but the dashboards do not show the conversion from raw inquiry to sales-accepted lead to opportunity to customer clearly enough. The decision then becomes political. The strongest voice in the room can matter more than the cleanest data.
Good dashboards reduce that friction by carrying context with the number. They show the metric definition, source, date logic, refresh time, exclusions, and owner close enough to the number that users do not need a separate investigation every time.
Research on dashboard provenance has made a similar point: many dashboards still fail to show enough information about sources and context, even though that metadata is essential for evaluating reliability. The business version is simple. People trust a number faster when they can see where it came from and what it means.
The fix usually starts with the handful of metrics that drive repeated argument: leads, pipeline, bookings, revenue, churn, active customers, utilization, gross margin, and conversion rate. Each one needs an approved definition, a known source, a named owner, a refresh rule, and a certified dashboard.
Once these are in place, the dashboard can guide the right decision with the right version of the number. Dashboard mismatch apart from creating reporting noise slows down execution too.
Dashboards show different numbers when teams use the same KPI label but apply different rules behind it. One dashboard may count leads by form submissions, another by CRM records, and another by sales-qualified opportunities. The label looks the same, but the metric is being built from different sources, filters, date fields, lifecycle stages, or refresh windows.
The first step is to trace the number back to its source. Check what the metric counts, which system owns it, which date field is used, how duplicates are handled, what exclusions apply, when the report refreshed, and whether any manual adjustment was made before the number reached the dashboard.
Dashboard mismatch, also called KPI mismatch, dashboard data inconsistency, or reporting discrepancy, happens when two or more dashboards show different values for what appears to be the same metric.
For example, sales may show $200,000 in revenue because it is counting closed-won bookings, while finance may show $50,000 because it is counting recognized revenue for the month. Both numbers may be valid, but they answer different questions. The mismatch becomes a problem when the dashboard does not explain which version it is showing.
Marketing usually reports a wider, earlier number. It may count form fills, campaign conversions, webinar registrations, content downloads, chatbot inquiries, or demo requests. Sales usually applies stricter filters before a record becomes usable: valid contact details, right geography, company fit, role, budget, intent, and no duplication.
A strong funnel dashboard should show these stages separately. Raw inquiries, valid leads, MQLs, sales-accepted leads, SQLs, opportunities, and customers are connected, but they should not be collapsed into one loose lead count.
CRM revenue often reflects sales momentum, such as closed-won bookings, contract value, or expected deal value. Finance revenue may reflect invoices, collections, recognized revenue, credits, taxes, or accounting-period rules.
A company should label these numbers clearly instead of calling all of them revenue. Closed-won bookings, invoices raised, cash collected, and recognized revenue belong to the same commercial journey, but they are different stages of it.
Dashboards change because data continues to arrive, sync, process, merge, or get corrected after the first report is viewed. A CRM may update immediately, a data warehouse may refresh overnight, analytics data may settle later, and finance may adjust figures after close.
This is why dashboards should show last refresh time, expected latency, and whether the current period is final. A live monitoring dashboard and a finalized monthly report should not be treated as the same kind of number.
Joins create wrong numbers when tables are combined at the wrong level of detail. If an order-level revenue table is joined to a line-item table and revenue is summed after the join, the same revenue can be counted multiple times.
The analyst should check what one row represents before and after the join. They should also compare totals before and after combining datasets. If revenue, customer count, pipeline, or usage suddenly changes after the join, the dashboard may be multiplying values rather than reporting them.
Teams return to Excel when the dashboard does not match the business reality they need for a decision. They export data, remove duplicates, fix campaign names, adjust revenue, exclude internal records, or apply rules the dashboard does not handle.
Excel is useful for investigation, but it becomes risky when the same workbook becomes the monthly reporting system. Repeated spreadsheet corrections should be moved into governed data logic, documented adjustment rules, or the approved metric layer.
A metric dictionary is a shared reference that defines important business numbers in operational detail. It should explain the metric name, formula, source system, owner, date field, filters, exclusions, duplicate rules, refresh frequency, and approved dashboard.
A weak dictionary gives broad definitions such as “lead means potential customer.” A useful dictionary defines exactly which records count, which records do not, and which system is trusted for the final number.
A semantic layer can help when the business has already agreed on metric definitions. It centralizes business logic so teams do not rebuild the same KPI differently across BI tools, CRM reports, spreadsheets, and SQL queries.
It does not solve the business debate by itself. Someone still has to decide what counts as a lead, customer, churned account, booking, recognized revenue, or active user. The semantic layer helps enforce the decision once the definition is approved.
A senior analyst should trace the number from source to dashboard. That means comparing definition, source system, date logic, refresh timing, filters, exclusions, duplicate handling, joins, manual adjustments, and ownership.
The output should be a plain-language reconciliation note. It should explain why the dashboards differ, which number should be used for which decision, which definition is approved, and who owns the metric going forward. That note often fixes the meeting faster than another redesigned chart.
Jun 19, 2026 / 39 min read

Jun 19, 2026 / 34 min read