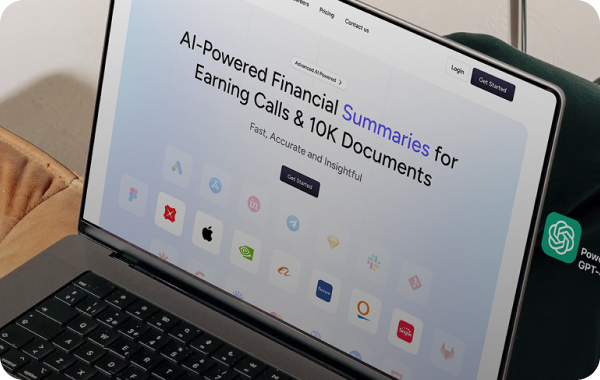
For Overthink, we built an AI platform that runs OpenAI, Gemini, and DeepSeek in one interface - so users can chat, edit images, and search their documents semantically without losing context or jumping between apps.

Overthink is an Italy-based software development business led by Francesco Picciariello, based in Gravina in Puglia (Bari). Francesco focuses on turning new technology into practical products that remove friction from daily work. His goal is to help people get more done with less effort by packaging complex tools into clear, usable workflows.

AI models are not interchangeable. They give different outputs, run at different speeds, cost different amounts, and perform better on different tasks. In real work, the “right” model depends on what you need at that moment - better writing, stronger reasoning, image capability, faster responses, or lower cost. And sometimes the model you want is slow or unavailable, so you need another option. Overthink needed one platform where users could switch models inside the same workspace - without losing context or moving to a different tool.

When Overthink’s lead developer resigned, the project paused because there was no usable documentation to continue from. After facing that kind of stoppage once, Francesco wanted a setup where delivery would not freeze again if a developer left, became unavailable, or needed to be replaced for any reason. VE fit for two reasons: it can onboard a replacement developer in as little as 48 hours, and the project is documented so a new developer can understand the current state and continue the work - without rebuilding context from scratch.
Different AI models produce different results. For the same task (writing content or generating an image) one model may give a better outcome than another. But if those models live in different tools, it becomes hard to compare outputs, reuse the same context, or keep the work moving in one place. Overthink needed a solution to these:
Compare models in one workflow: Users needed to run the same request across OpenAI, Gemini, and DeepSeek inside one workspace, so they could quickly compare results for the same content or image task without rebuilding context in separate apps.
Repeating the same prompt: Switching tools often means retyping or re-pasting the same instructions again and again.
Losing context mid-work: When the workflow is split across apps, it is easy to lose the thread of what was decided, what was tried, and what worked.
Account and billing overload: Multiple logins, multiple subscriptions, renewals, and cancellations add mental load and wasted spend.

Making this work meant building a real platform layer, not a wrapper around a single model. OpenAI, Gemini, and DeepSeek have different APIs, message formats, context limits, rate limits, and edge-case behavior, but the product still had to feel consistent and predictable. That required normalizing outputs, handling streaming responses, and keeping context usable even when the underlying providers behave differently.
A multi-model product also has operational challenges. Models can be slow, rate-limited, or temporarily unavailable, so the system had to handle timeouts, retries, and model switching without forcing users to restart work or lose context.
Beyond text, the platform needed reliable pipelines for image modification, semantic file search/document Q&A, and link-based inputs (web and YouTube). Each workflow required its own processing and failure-handling, while still appearing as one simple assistant.
Finally, it had to ship as a real product from day one: secure access (JWT), payments (Stripe), and reliable deployments with separate frontend and backend releases.
The Solution
Francesco hired a VE developer (Nitai) to restart the project after his in-house lead developer resigned. The handover came with no usable project documentation, so the work could not continue by simply “following notes.”
To get the project moving again, VE focused on three fixes: restart delivery fast, make large-file Q&A reliable, and scale work in parallel without losing context.
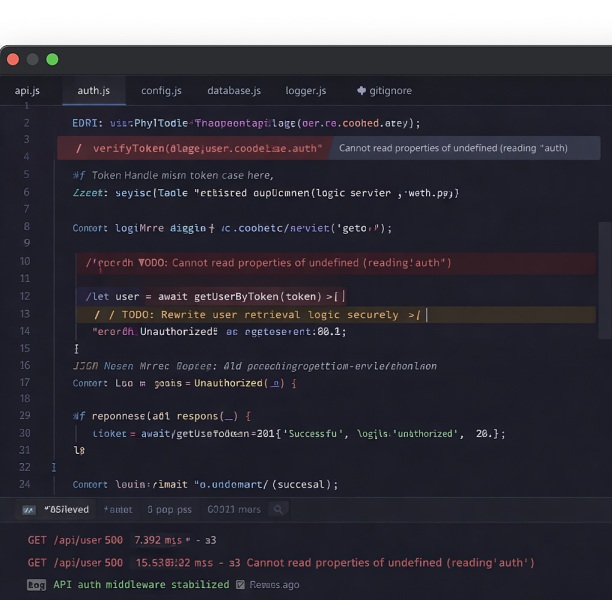
With no usable handover notes, the first job was to make the current codebase safe to continue. Nitai started by mapping what already existed - what works, what breaks, and what is missing - then stabilized the baseline, so new features would not be built on top of unknown behavior.
With no usable handover notes, the first job was to make the current codebase safe to continue. Nitai started by mapping what already existed - what works, what breaks, and what is missing - then stabilized the baseline, so new features would not be built on top of unknown behavior.
These are the first 3 steps:
Baseline setup: Nitai first made the project runnable again end-to-end. He recreated the local setup and deployment baseline by documenting the exact prerequisites (keys, environment variables, service endpoints), confirming the JWT auth flow works, and validating the CI/CD path (GitHub Actions → DigitalOcean) so changes could be shipped without guesswork.
Environment reproducibility: He then made the environment repeatable for anyone joining later by adding an .env.example (so required config is explicit), pinning dependency versions where needed, and standardizing how supporting services run (for example, bringing up Qdrant in a consistent way so vector search behaves the same across machines).
Key flows: With the baseline stable, he walked the product through the core flows as “smoke tests”: sign-in → chat on each provider (OpenAI/Gemini/DeepSeek) → image modification path → file upload → chunking/embedding → Qdrant retrieval → answer generation, plus web/YouTube link input, so breakpoints were found in real usage paths, not in isolated code.
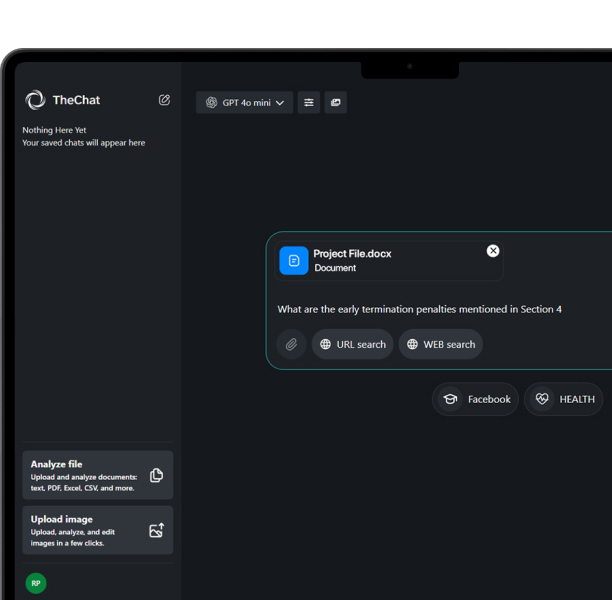
One of the most important features to get right was “document Q&A.” A user uploads a large file, like a financial report, a contract, legal documentation, or compliance rules, and asks questions using the document as the source (of truth).
One of the most important features to get right was “document Q&A.” A user uploads a large file, like a financial report, a contract, legal documentation, or compliance rules, and asks questions using the document as the source (of truth).
These are the first 3 steps:
In regulated environments like banking, insurance, and healthcare, those answers can drive approvals, rejections, escalations, and sign-offs, and later they may need to show exactly what policy clause or document section the decision was based on. If the platform does not retrieve the right text from the document first, the model may answer based on guesswork instead of the file. Here, AI has to be right, not just helpful.
The challenge is that models can only read a limited amount of text at one time (around ~8,000 tokens here). When a file is longer than that, the model only sees a slice of it. So it can miss the clause or section that matters and still produce a confident answer (that might not be a true answer) based on partial context.
Our developer fixed this by redesigning the document Q&A pipeline. The platform automatically splits each uploaded file into 200-word chunks with a 100-word overlap, converts those chunks into embeddings, and stores them in Qdrant. For every question, the system embeds the query, retrieves the most relevant chunks, and only then generates the answer. This kept responses accurate even when the document was much larger than the model’s reading window.

As the scope grew, the work had to move in parallel. Alongside the core build, Overthink needed YouTube link analysis to move forward without slowing releases. Francesco added Mousumi Dey (Sr. Software Developer) from VE, and she ramped up fast because the project documentation was already maintained and easy to follow. She could see what was already built and what was next from day one, with almost no handholding. This is how VE makes “add one more developer” painless—through shared documentation habits.
Text Conversation
The core experience was straightforward text conversation, with the ability to run the same chat flow across OpenAI, Gemini, and DeepSeek. This made model choice part of the workflow, without changing how people interact with the product.
Image Generation
The platform supports image generation using DALL·E 3, along with image upload and analysis through Gemini. This allowed image work to sit inside the same product flow instead of needing a separate tool.
File Upload & Document Q&A
File upload was designed for document Q&A, not storage. Files are processed so questions can be answered even when documents are very large and cannot be read in one go, using chunking, embeddings, and Qdrant-based retrieval.
Web Search
Web search was added so the assistant could handle questions that require online context. The goal was to keep “search and answer” inside the same interface, instead of sending people out to separate browsing tools.
YouTube Link Analysis
The platform supports YouTube URL analysis so a video link can be used as input for summaries and Q&A. This expanded the assistant beyond typed text and documents to include video-based content in the same workflow.
Models & Integrations
The platform was designed to work with multiple model providers through a single backend flow. It integrates OpenAI (text, DALL·E 3, embeddings), Google Gemini (1.5 Pro and 2.0 Flash for image and file analysis), and DeepSeek as an additional model option.
Payments & Access Control
The product includes JWT-based authentication to secure APIs and user sessions, and Stripe integration to handle payments. This made the platform usable as a real product with controlled access, not just a demo.
Infrastructure & Deployment
The system runs on three DigitalOcean droplets - one for the frontend, one for backend APIs, and one for vector database operations. Delivery used GitHub feature branches and GitHub Actions to automatically deploy changes to DigitalOcean when merged with main.
Overthink now runs OpenAI, Google Gemini (1.5 Pro / 2.0 Flash), and DeepSeek through a single interface.
The platform supports text conversation, image generation and analysis, file upload, and web plus YouTube link analysis.
Documents are handled through chunking, embeddings, and Qdrant retrieval so answers stay accurate beyond the ~8,000-token reading window.
He (Nitai) was the best developer I worked with because he really understands my requirements. He's supportive and smart, and fast in his work. He also provided me with advice on the architecture.”
Francesco Picciariello
CEO, Overthink, Italy